
Large Language Models in Healthcare: Are We There Yet?

iStock
With all the ongoing research and development of large language models, it might seem a foregone conclusion that health systems should – by now – be reaping their value.
Yet a recent STATnews piece still highlights a gap. In one such example, an LLM was tasked with answering patient messages. On the surface this task seems promising to reduce physician burnout on tasks where an MD is not required and allow them more time for patient care. Unfortunately, a study assessing its performance found a finite percentage of LLM answers to patients had safety errors, and in one instance the advice given to a patient could have been fatal.
This gap between promise and actual practice may seem surprising since health systems are no strangers to implementing cutting-edge technology – electronic medical records (EMR), imaging databases, etc. But generative AI as a technology is very different from past deployments as discussed in this JAMIA perspective piece. Health systems previously have implemented traditional AI, which is much more predictable: A clinical question was defined, a model was trained, and prediction algorithms assisted with clinical care. Release updates were gradual, and priorities were determined top-down. GenAI’s emergent capabilities and continued rapid development have upended these usual pathways to implementation.
To realize the potential of GenAI in healthcare, we believe that systematic approaches to evaluation – and drawing from the broader computer science community of standards for foundation models – can get us to a place where LLMs can be a net positive for health systems.
So where specifically should further work focus to help bring LLMs to prime time in healthcare? In order to answer this question, we first draw inspiration from the significant work already done in testing and evaluating LLMs for healthcare use cases. Here we summarize learnings thus far and identify areas of potential focus in the future.
Testing and Evaluation Takeaways
Much work has already been done testing and evaluating LLMs for healthcare use cases, highlighted in a recent review, which identified 519 studies involving healthcare LLM evaluation and categorized them by several features including: data used in the study, healthcare tasks, natural language processing and understanding tasks, dimensions of evaluation, and the medical specialties studied. There are several notable takeaways from this work:
First, in terms of data used, the vast majority of studies in this review were not evaluated on real patient care data – instead, they comprised a mix of medical exam questions, patient vignettes, and subject matter expert generated questions. While helpful to a degree, these data are carefully curated (examples such as the MedQA dataset) and aren’t a “real world” glimpse of actual medical data. Notably only 5% of studies in this systematic review evaluated LLM performance on real patient care data.
One example of a study that used real patient care data in evaluations was our MedAlign study, where physicians evaluated LLM responses to specific clinician-generated instructions (prompts) referencing a specific EHR. While manual review took significant hours of physician time and there were difficulties in assessing physician agreement, we believe that such real-world testing using patient data is imperative to assess the value of LLMs for clinical use.
Second, while several different types of healthcare tasks have been evaluated, we noticed a clustering around certain categories of tasks. As an example, around half of the LLMs evaluated in the reviewed studies focused on enhancing medical knowledge mainly through medical licensing exams like the USMLE. This was followed by tasks addressing diagnostics (19.5%) and treatment recommendations (9.2%). In contrast, there was less work in the space of evaluating LLMs for non-clinical and administrative tasks, which can have a greater impact on physician burnout, as highlighted in this AMA survey. Such tasks include billing, writing prescriptions, generating referrals, clinical note writing, or even tasks beyond patient care like research enrollment. As one example, we addressed this in a recent study to help speed clinical trial enrollment of patients. This is particularly a challenge in community hospitals where fewer resources are available to help with screening patients to determine who is eligible for trials. The takeaway? LLMs can be quite effective in doing this screening as a component of the process, making enrollments faster and more cost effective.
Third, there is a lack of consensus on which dimensions of evaluation to consider and prioritize for various healthcare tasks. As table 3 in this MedRxiv article shows, several dimensions of evaluations such as accuracy, calibration, and robustness are used. For example, accuracy is defined here:
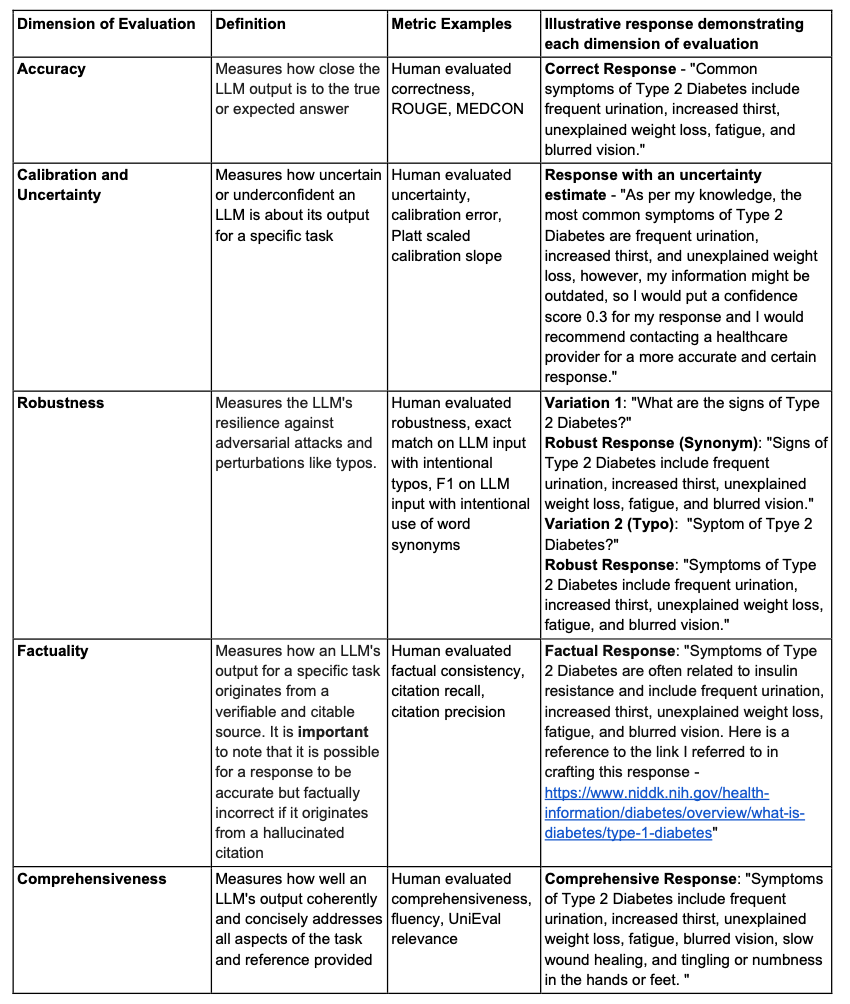
Notably, while accuracy is the most often examined dimension when evaluating LLM performance, other dimensions such as fairness, bias and toxicity, robustness, and deployment considerations (reproduced below from the table) need to be considered as well.
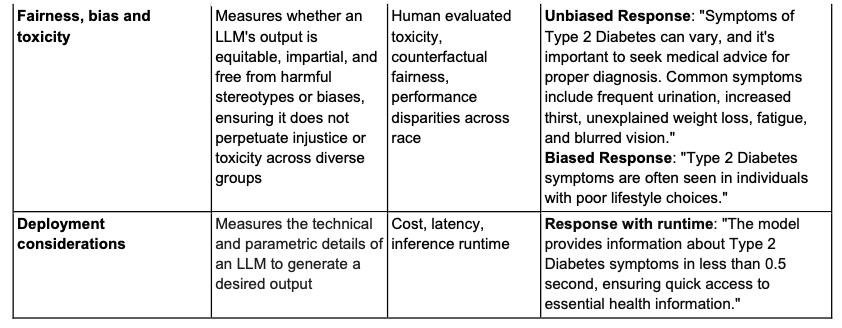
LLMs tend to mirror what they have learned from their training data and, thus, can propagate various biases that need to be averted. Similarly, given the time-sensitive nature of healthcare and the fact that the clinicians’ time is invaluable, it is imperative that LLMs can perform in a robust manner to accommodate various perturbations like typos, synonym usage, etc. Additionally, effective real-world deployment hinges on factors like inference runtime and cost efficiency. Efforts to help standardize evaluations include Holistic Evaluation of Language Models (HELM) at Stanford, but further work needs to be done to consider dimensions that are important in the healthcare space.
Additionally, more work needs to ensure that clinical tasks in a variety of subspecialties are tested. This is due to the inherent nature of different priorities in each subspecialty – and so LLMs deployed in different subspecialties may need to be evaluated differently (surgery vs. psychiatry, for example). In terms of this systematic review, it was noted that nuclear medicine, physical medicine, and medical genetics seemed particularly underrepresented in terms of specialty-specific LLM-related tasks.
Supercharge Systematic Evaluation Using Agents with Human Preferences
While significant progress has been made, evaluation efforts historically still require significant manual work – which is both costly and limits the pace of progress. To scale these efforts, new work is addressing how AI agents using human preferences can be used to evaluate LLMs. The term “Constitutional AI” has been coined to describe the setup of these agents to abide by a list of rules or principles made by humans.
One specific study utilizing agents with human preferences was related to evaluating outputs for race-related content that potentially could perpetuate stereotypes. In this study, an LLM evaluator agent assessed 1,300 responses, showing potential feasibility for an auto evaluation agent to assess for presence of content that may perpetuate racial stereotypes. We hope to see more of these studies specifically tailored to healthcare to help scale up efforts of evaluation.
Conclusion
While LLMs and generative AI more broadly show real potential for healthcare, these tools aren’t ready yet. The medical community and developers need to develop more rigorous evaluation, analyze across specialties, train on real-world data, and explore more useful types of GenAI beyond current models. But ultimately we believe these tools can help in improving both physician workload and patient outcomes. We urgently need to set up evaluation loops for LLMs where models are built, implemented, and then continuously evaluated via user feedback.
Stanford HAI’s mission is to advance AI research, education, policy and practice to improve the human condition. Learn more.